
Ian here—
What follows is my talk from SCMS 2016 in Atlanta, GA. You can follow along with the visual presentation here.
The moving image and the graphical user interface: they are often regarded as two separate forms, with their own unique histories, and with resulting divergent aesthetics. Recent years, however, have seen this division beginning to break down, as the GUI has gradually invaded moving-image storytelling.
Representations of the graphical user interface have a long history in science-fiction, from the augmented reality elements that clutter the cyborg’s point-of-view to the fantastic potentials of human-machine interfaces.


More recently, it is not imagined technology requiring new forms of visual address, but instead everyday, quotidian technology. Visual storytelling has, for instance, struggled to adapt to our preferred methods of communication in the twenty-first century, as cinema and television have frantically searched for ways to visually integrate things such as text message conversations into the visual frame. Sometimes, this results in an insertion of hovering GUI elements into the depicted space of the scene.


More radical experiments see filmmakers abandoning traditional shooting and visual presentation of cinematic space altogether, instead condensing their action so that it can be entirely narrated via the screen interface of a Mac.




From one angle, we can consider contemporary GUI technology as a problem to be solved: the realities of contemporary human communications technologies present a hurdle for classical visual storytelling, a set of constraints that can potentially be productive, but do require some degree of lateral thinking to get around. But this is not the only way of considering these recent mutations and convergences. The “GUIness” of moving images in recent years—if you’ll permit me a neologism—is not solely a product of visual storytellers telling GUI-centric stories. Sometimes, text and other GUI-like elements arrive in the frame because they present a solution to some long-term storytelling problems—a solution that, presumably, viewers will be comfortable with at this particular historical moment, given the prevalence of GUI-based devices in our everyday lives.
In this paper today, I would like to focus on one long-standing problem that the use of GUIness has recently presented one solution to: The problem of the detective’s gaze.
Moving-image variations on detective fiction have long struggled in letting viewers in on the point-of-view of characters able to keenly pick up on relevant environmental details. Cinema allows us to see a crime scene from the position of a detective, but it is harder for us to see it how the detective sees it, with all of their relevant expertise. How can images convey a mode of visual experience that is thoroughly shot through with intuition? What is it like to have a hunch? Can you see a hunch—and, if so, what does it look like?
Before GUIness, divergent answers to these questions abounded. Over the past several decades, the pursuit of ways to visualize hunches, intuitions, and “lightbulb moments” has been one of the major drivers of stylistic innovation in, for instance, television procedurals. For instance, we see the skills of FBI profilers presented as the ability to have “glimpses of madness”—moments in which they saw the world in a manner just as askew as the psychologically deviant criminals they were tracking.


Meanwhile, when forensic investigators crack the code of physical evidence, we are treated to graphic views of the physical processes within bodies (whether the evidence in question is being applied to a criminal investigation, or a medical one).


For a look at what GUIness has wrought, one can contrast these shows to the more recent stylings of BBC’s Sherlock (2010–). Here, the expressionistic visuals of serial killer and forensic shows of the 1990s and early 2000s are jettisoned, and we begin to see what GUIness can offer detective fiction.
Take, for example, a scene of Sherlock Holmes examining a victim’s body in the first episode of the show’s first series, “A Study in Pink” (2010).
Here, the intrusion of clean, white, san-serif text into the visual scene specifies those relevant details that Sherlock’s expert gaze can pick up on—and, presumably, viewers’ unaided, non-Sherlock eyes could not.
Beyond the realm of his perceptive prowess, Sherlock’s memory also receives a GUI overhaul. In series 2, episode 2, “The Hounds of Baskerville,” as Sherlock retreats to his “mind palace,” his associative recollections are visually presented via the character swiping blocks of text around in the space immediately surrounding him. Here, an ancient mnemonic technique is staged as if it were just steps away from the futurist interface imaginings of Minority Report.
What is especially noteworthy about these stylistic flourishes is just how nonchalant the show is about their motivation. In the modern graphical user interface, text and images freely interpenetrate each other—hover over an image on a webpage, or an unfamiliar icon, and you’re likely to see a textual description or explanation pop into view. Why not, then, visually present points of view that are shot through with expertise the same way our own views are so often shot through with information? Given the way most of us interact with screens, it is of little surprise that contemporary visual metaphors for human knowledge, expertise, and intuition might bend toward such points of reference as Google Street View, the search bar auto-fill, or even the humble alt-text.




How did we get here? How have audiences become so accepting of the conceit that the visual language of movies and television dramas should be just as shot through with textual information as an augmented reality app? What is the missing link here, between GUIs and visual storytelling? Here, I would like to propose that videogames have played no small role in this turn toward GUIness. In particular, I believe we can draw a clean line between how games have used GUIness to approach the detective’s gaze, and the GUIness currently exhibited by shows such as Sherlock.
The mystery genre has historically posed an interesting challenge to the videogame form. Often bereft of a strong intervening character performing a mediating function for the work of detection, videogames have had to work harder to endow their players with the ability to pick up on relevant environmental clues. The visual translation of intuitive observation, then, becomes strictly a problem of user interface.
The unavoidable realities of technological limitations helped set precedents in this area. In 1981, the development team Adventure International released The Curse of Crowley Manor, a rather unsubtle occult mystery tale that finds a Scotland Yard detective fighting a demon, for the Apple ][ home computer. An early entry in the graphic adventure genre of computer games, technological limitations require the game to be controlled through text parser, rather than through any direct graphical interaction with the images presented.
Players of the game, then, have a distinctly dual access to the game’s world. If they navigate into a room of the game’s titular Manor, they will see an illustration of this room being elaborately drawn on the screen. In order to actually do anything in this room, however, they must hit the “return” key on their keyboard, at which point they will be greeted with a text screen, where they can read a description of the space they are in, and type in a command to continue.


The image view prizes phenomenal fidelity, attempting as “realistic” a point-of-view onto the proceedings as the graphical horsepower of the Apple ][ could allow. But it does little to pull the players’ attention to relevant details in the environment: that is strictly the purview of the text screen. The text screen focalizes our attention: If an object is verbally listed among the contents of the room, it follows that players should try to interact with it. Sometimes, interacting with it will reveal something new in the room which can be picked up and additionally manipulated—listed under the room’s “visible items.” A UI dichotomy is drawn, then, between fidelity and focalization.
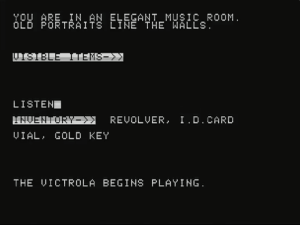
Here, for instance, is the music room of Crowley Manor: depicted in blobs of garish color, it visually sets the scene, without actually allowing for much detection. To actually interact with the scene, we must switch into the more focalizing text mode. Upon typing “LOOK MUSIC ROOM,” we are presented with a verbal description that clearly names the objects present. Further use of the “look” command makes us privy to the detective’s gaze: suddenly, more relevant details are revealed about the room, which we may not have noticed in the graphical rendering (or, in fact, may not have been graphically rendered at all). “LOOK VICTROLA” produces the observation “IT HAS A CRANK ON THE SIDE.” “LOOK CRANK” reveals that “A GOLD KEY IS LODGED IN THE CRANK.” From this point on, “GOLD KEY” is listed within the “visible items” of the scene—a verbal list presented on the text screen of items that are visible to our detective intermediary, even though they are pointedly not visible to us as players in the game’s graphical renderings.
There are technical reasons we could point to behind discrepancies such as this that pop up between the image and focalizing text. There is a very real limit to the detail Adventure International was able to add to these Apple ][ images, and disc storage limitations would have rendered it impractical to include things such as more detailed close-up views of scenes. Still, though, the stylistic choices made in finding a way around these limitations have the distinct effect of invoking an intervening consciousness—the gaze of a detective character more keenly embedded in this world, more perceptive than our rudimentary visual access can allow us as players to be, able to spot details that are invisible to our own eyes. Able, as well, to exceed our narrow sensory access to this world in other channels—as when the command “LISTEN” upon successfully turning the victrola crank produces the response “THE MUSIC IS MOZART,” despite the fact that the game itself is entirely without musical accompaniment.

And so it is established: this basic dichotomy between the presentation of narrative space in a visual manner, with some amount of fidelity toward how we usually perceive scenes, versus a more functional focalization of attention, often accomplished via the introduction of text.
We are decades, now, since The Curse of Crowley Manor, and mystery-themed adventure games have long since shed archaic text-parser interfaces and distinct text and visual screens. However, the distinction between image-based fidelity and text-based focalization remains, now combined into a single, augmented-reality style interface. Sherlock Holmes: Crimes and Punishments, from 2014, the most recent entry in developer Frogwares’ long-running series of official licensed adaptations of Sir Arthur Conan Doyle’s stories provides a strong example.
In this brief clip, we see the player, as Holmes, navigating through the elaborately-rendered changing room of a Roman bath. Although some objects in the room, such as a pile of towels, are mere extraneous detail, others, such as suspects’ clothes, are marked as significant clues by a hovering UI element, including a text description, and an icon that very handily turns green once the player has exhaustively investigated the clue in question. Some objects support more robust interactions than others—including, here, an ice bucket that has several aspects that can be investigated by rotating it, and hovering the cursor over different relevant areas. (And, yes—spoiler alert—the disappearing weapon was, in fact, an icicle.)
On a purely functional level, there is nothing particularly surprising going on here at all. Sherlock Holmes: Crimes and Punishments is just doing what videogames have been doing for years: highlighting objects that can be acted upon, to better differentiate the “game” aspects of the environment from those superfluous details that are there only for the sake of graphical verisimilitude. On the level of motivation, however, a certain elegance abounds. Of course there should be bits of text pulling out relevant details of the environment—we are, after all, inhabiting the detective’s gaze of Sherlock Holmes, whose experience of the world is shot through with both specific expertise and general deductive capabilities that we could never hope to have. The augmentations we, as players, are privy to are a way of extending character alignment (to borrow a term from Murray Smith): our access to what Sherlock Holmes knows and feels.[i] As our avatar, Holmes is also in some sense our visual narrator—we see, roughly, what he sees, and although we cannot see things precisely how he sees them, the game’s textual, visual, and acoustic flourishes help to fill the gap, to cue us in to the richer perceptual experience Holmes enjoys.
This motivation for the game’s textual UI elements becomes especially clear in its interrogation sequences. Here, players are given an opportunity to break from questions and instead undertake a close visual analysis of their subject. Hovering over relevant physical traits of a witness or suspect’s person will allow the players to pull out details about their history or personality, added to a list of adjectives that hangs in the interface’s upper righthand corner.
Sometimes, this tactic utterly fails to give us any sense that we inhabit a more perceptive character—for instance, when looking at the face of a foul-tempered aristocrat reveals only that he has an “arrogant look” and “disdainful mouth.” Other moments, though, are more successful. Examining one witness in the game, for instance, Holmes can tell from his haircut that he lives alone (which we, as players, most certainly cannot), and successfully spotting a telegram in his pocket allows Holmes—and the player—a chance to later call him on an inconsistency in his story.
Comparing such moments in Crimes and Punishments with Sherlock, we see a convergence in terms of both form and function. In both cases, although we see a scene, we don’t see it in precisely the same way a brilliant detective might, and so text must intervene. Rather than screening us from the world of the fiction, as Stanley Cavell would have it, these genre pieces instead draw inspiration from modern GUI environments to explode the possibilities of the screen, layering multiple types of access to diegetic information and character interiority in an image that is rich in epistemic possibility.[ii]
Media history is littered with models of straightforward genetic descent: whether we’re operating under McLuhan’s dictum that the “content of a medium is always another medium,” or Bolter and Grusin’s “remediation,” we possess no shortage of models that can explain how one medium begets another medium, superseding it by subsuming its functions while adding new possibilities. Histories of style, however, must take care to be more precise—to allow for moments of functional isomorphism between the “old” and the “new,” moments in which evolutionary convergence upsets the logic of rote evolutionary descent. The GUI proved that screen images could be harnessed to communicate interactive possibility. Computer games further illustrated that visual storytelling could be productively combined with text-enhanced GUIs. This hybrid mode of address proved itself quite adept at pulling players into an epistemic approximation of character thought processes, allowing for successful depictions of the intuitive expertise of the detective’s gaze. And these insights did not stay within the realm of games: GUIness has bled out, expanded, and infiltrated older, neighboring moving image forms.
Along the way, it has blurred diegetic boundaries, and re-coded the visual language of character subjectivity to look very much like, what in the 1980s, used to be reserved for alien forms of machine intelligence. As “as we may think” has shifted to “how we do think,” the GUI has become an inescapable metaphor for human perceptual prowess and cognitive mastery, one that cinema and television could scarcely avoid. How better, after all, to visually represent human intelligence than through its tools?
[i]. Murray Smith, Engaging Characters: Fiction, Emotion, and the Cinema (New York, NY: Oxford University Press, 1995).
[ii]. Stanley Cavell, The World Viewed: Reflections on the Ontology of Film, Enlarged Edition (Cambridge, MA: Harvard University Press, 1979), 24: “A screen is a barrier. What does the silver screen screen? It screens me from the world it holds—that is, makes me invisible.”
